
Running Projects: A Systems Approach

It can be daunting for an engineer to take on leading their first large project. They may have a dozen engineers, multiple work streams, intense reporting requirements, and tight deadlines. Fortunately, we can leverage a strength any good software engineer has: systems design.
You can use systems thinking and design to break down a project from technical design to tasks, organize those tasks into work streams, set up reporting, and provide accurate estimates to your stakeholders.
You can accomplish this by doing the following steps:
Find the work streams
Model dependencies between the work streams
Breakdown each work stream
Find the KPIs for each work stream
Build the project system
Monitor and adjust
We’re going to look at two examples inspired by projects I’ve led, modified to protect proprietary information. For the first example, we’ll discuss a service that consists of an API that takes in asynchronous work requests and a workflow that processes those requests. For the second example, we’ll talk about a major project that touches over a dozen services with hundreds of changes.
Find the work streams
Typically, your software will have boundaries that separate components and you can leverage these to separate your work streams as well. A good tech design will help guide you through this process. We’ll use this when we go through the first example above.
If there isn’t a tech design, you may need to look at the work itself. Assess the work that needs done and find any common patterns in how it will be done. Those patterns will help us define the work streams in the second example.
Model dependencies between the work streams
Work streams may have dependencies between them. These dependencies will eventually result in bottlenecks where one work stream is waiting on another. To find these, inspect the boundaries in your software. Are there API definitions that need completed? Database models? Message formats? Figure these out, and prioritize resolving these first.
Breakdown each work stream
For each work stream, start at a high level and find which pieces can be done independently. For instance, you may be building two sets of CRUD APIs for two different resources so you can build these separately. For each resource, you may need to define a data model which will prevent working on each of the Create, Read, Update, Delete APIs. You don’t want the Create and Delete APIs operating on completely different data models! Model these dependencies between high level tasks. As you do this, you’ll get a sense for what can be done in parallel and what tasks are blocking others.
Find the KPIs for each work stream
If you’re leading a project of any size, there will be someone wanting to know how progress is going. For some projects, it may make sense to assign task points and try to report the progress on those. For some projects, that could be a complete waste of time and something like ticket count would be a better fit. For others, you may report on the completion of each sub workstream, such as which APIs are done and which aren’t. Work with your stakeholders to find the right way to report progress.
KPI (Key Performance Indicator) is business word to many engineers, but it’s really just a metric to measure the success of a particular system. As software engineers, we know how to measure systems. Consider each of your work streams and what you would need to measure to report status to your stakeholders.
Build the project system
Now, we have the information we need to start figuring out how the project should function. We have our work streams, we understand the dependencies, and we know how many people we have. You’ll generally want to assign a single owner to each work stream, unless a stream is especially small and can be easily managed by someone with split attention. Model out the project as you would any other system, including reporting lines and work streams.
Monitor and adjust
No plan survives first contact with reality, and your project system is no exception. People will get sick, work streams will move more slowly or more quickly than expected, priorities will shift, and so on. Keep a close eye on the system, identify constraints, and eliminate them.
Example One: Async Workflow
For this example, we have a simple system where an API ingests work that a workflow completes in the background. Here’s the (very) high level technical design.

API writes the work request to a datastore
The datastore event triggers the workflow
The workflow performs the work and marks the request as completed
When the caller requests the status, the API reads from the datastore
Let’s go through the process outlined above to build a project system that can deliver this software system.
Work Streams
First, we can see three main parts of the system: The API, The Datastore, The Workflow. In this case, the work streams fall out of the architecture diagram. Let’s start by considering each of these a separate work stream and move to the next step.
Dependencies
Looking at the diagram, we can see that The API and The Workflow depend on The Datastore. The API and The Workflow are fairly independent, though. There may be some common code, but the bulk will be in how they interact with The Datastore. We can rework our diagram to show these dependencies.

We have a problem, though. According to this diagram, we need to complete The Datastore before we can start work on The API or The Workflow. This means those two work streams will be stalled waiting on the third, which isn’t great. We want to go fast.
Fortunately, with a strong architecture in our code, we can abstract away the implementation detail of The Datastore. I won’t get into code architecture in this post because it deserves its own, but just imagine The API’s code and The Workflow’s code operate against interfaces instead of making database queries.
With this abstraction, we can break the dependencies and work on all three work streams simultaneously.
Breakdown The Work
Now, we need to get some tasks. I recommend using a simple bullet list to start. For the API workstream, we might produce something like this:
API Infrastructure
Create containers
Create load balancer
CreateFoo
Define API model
Implement
Testing
ReadFoo
Define API model
Implement
Testing
UpdateFoo
Define API model
Implement
Testing
DeleteFoo
Define API model
Implement
Testing
And so on and so forth. Once you have your bullet list, it’s worth doing a check for dependencies again. We want to make this maximally parallelizable. Fortunately, if you are following a strong testing pyramid design, these can all be done individually. You can build the CreateFoo API and test it without having any real containers running. You can continue breaking this bullet list down, perhaps a task for each test. At this point, we’re talking tasks and not work streams, so we’ll leave it here.
Reporting and KPIs
For this example, we can probably follow a traditional task pointing system. The work is fairly well understood and easy to estimate. Once you go through your planning sessions and assign points as a team, you can just report progress on those points as your KPI.
The Project System
Let’s say we have 5 engineers that can work on this project: Alice, Bob, Charlie, and Dani. The last one is the project lead: you.
We have three parallelizable work streams: The API, The Workflow, and The Datastore. We’ll assign Alice to The API and Charlie to The Workflow, as they need opportunities to lead a small project. You must delegate ownership of these streams to them. We’ll get into delegation in another post and how to use it to empower your fellow engineers and help them grow. The Datastore is especially concerning, as you need to make sure the data model is extensible. You’ll take that responsibility as the most experienced engineer on the team.
This leaves Bob and Dani unassigned. The Datastore doesn’t have a large volume of work, so you assign them to Alice and Charlie’s work streams respectively.
Since Alice and Charlie own their own workstreams, they only need to communicate with you insofar as escalating major issues or resolving conflicts on the boundary. You are the only one communicating with stakeholders, so they have a single point of contact and there is no confusion when communicating.

This diagram illustrates the system for the project team. You are not interacting with Bob and Dani since Alice and Charlie are directing them. The Stakeholder is not communicating with anyone else, ensuring clear communication from the project team. Any issues in the work streams are escalated through you, the project lead.
Monitor and adjust
When we executed this project, we encountered some unexpected complexity in the Datastore that resulted in almost two weeks of extra planning and another two weeks of implementation work. Once we realized that it was going to be more complex, we were able to pull a more experienced engineer off of the Workflow workstream to assist. The API also ended up being simpler than expected, so we were able to rebalance one engineer from that workstream to the Workflow.
Pay close attention to how your project system is behaving and adjust accordingly.
Example Two: Multi-Region Support
For Example Two, we’re going to look at a project with a larger scope and a different structure. This project is to take our system consisting of around a dozen microservices and enable it to launch in any AWS Region. Until now, the service had only needed to run in one region, so there are a lot of places in the code that just refer to the one region. Further, we need to consider data replication across regions and a failover mechanism should one region stop functioning.
Work Streams
For this project, we could structure the work in a few ways. For the first pass, we look at enabling this service-by-service, where we would define our work streams based on the service, so a dozen work streams. That’s a lot of parallel work to track and doesn’t really look at the entire system.
The first step we’ll take is to get an idea of the work that actually needs done. After completing an audit, we find the following:
Hundreds of static references to a specific region
Twelve datastores that need to support cross-region replication
Three workflows that need to support some kind of cross-region exclusivity
Updating deployment pipelines to support multiple regions
After doing this audit, we can really break it down into four major types of work:
Static Configuration Fixes
Datastore Replication
Workflow Exclusivity
Deployment Pipeline
Since these types are all likely to have similar solutions, we define these as the work streams. This will allow the people working each stream to focus within a particular problem/solution space, and we can assign them based on their skills.
Dependencies
Going through the dependency modeling exercise, we know that Datastore Replication and Workflow Exclusivity are going to be blocked on the Static Configuration Fixes. We can’t really test solutions for cross-region replication or exclusivity locks when the services can’t even be deployed in multiple regions due to hardcoded values. Updates to the Deployment Pipeline are going to have similar concerns.
Unlike Example One, we can’t really abstract the dependencies behind interfaces to break them during development. We can do some exploration and design in the later work streams, but not really much more. We need to figure out how to structure the work so that the blocked work streams can actually get started.
Looking at the work streams, we identify specific tasks along another dimension: the microservice. Let’s look at three hypothetical microservices: Thor, Odin, and Fafnir.
As we see, we actually have twelve divisions of work to go on. Further, we know that Fafnir needs Odin present to function, and Odin needs Thor. We model our dependencies like this, which gives us an ordering to do the workstreams in for each service.

Let’s model this as a directed graph, taking into account the dependencies in the actual work, and the order we want to do these services in. This will come in handy later.
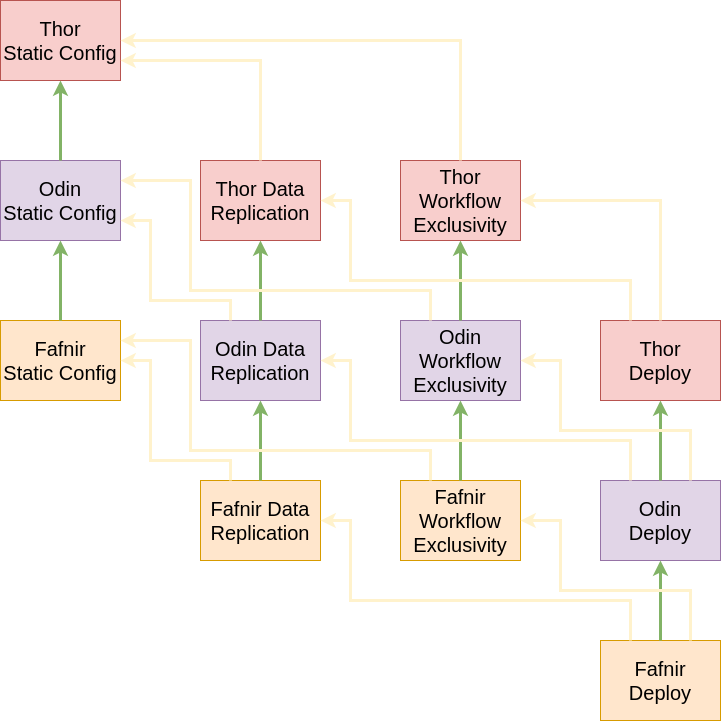
Breakdown the Work
For each of these, we’ll do the standard work breakdown process as covered in Example One.
Reporting and KPIs
For a project like this, it may be tempting to report based on the work streams, but the reality is that your stakeholder doesn’t care about the implementation details of your services. They want to know how far you are through the service list that needs fixed and when you can launch in the new region. For this project, we actually want to report on that extra dimension we added above, the service. But we are planning to do the work based on the type of work, not the service. Our stakeholders are going to complain if we say no services are done, then suddenly they all are, so we need a way to approach this work so that we can report service-by-service, but allow our engineers to work in a specific problem space.
The Project System
In a case like this, we need to embrace a system inspired by graph traversal. We will walk the dependency graph, actively working on any nodes that have no blocking dependencies.
First, we’ll have our Static Configuration team tackle Thor’s configurations. When this is done, we have unblocked the Datastore Replication and Workflow Exclusivity work streams. We’ve also freed up the Static Configuration workstream to move on to Odin.

Now, we have three parallel work streams running: Odin Static Configuration, Thor Data Replication, Thor Workflow Exclusivity. Let’s say they all finish at roughly the same time, so we can update our graph. Now, we have all four work streams running.
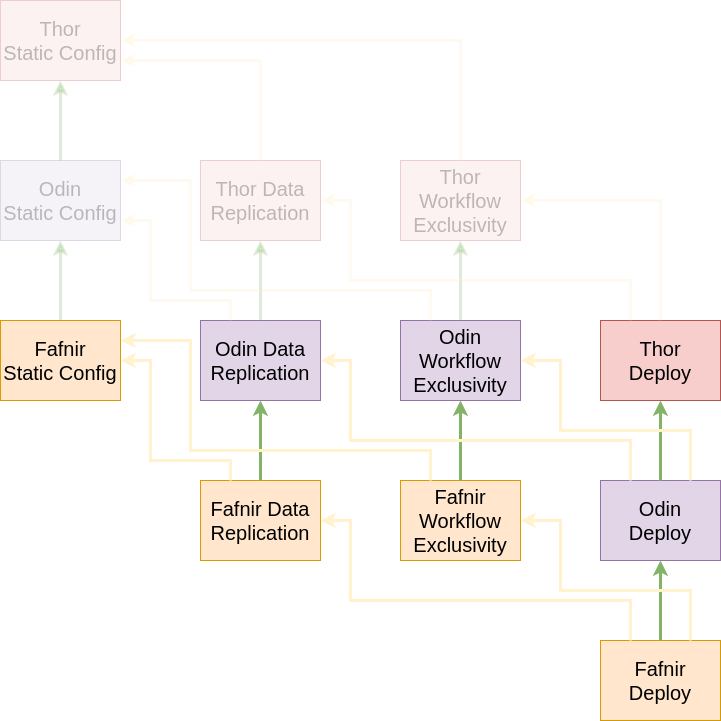
In the next phase, we will have completed the Thor Deployment Pipeline work, which will allow us to report that Thor is completed to our stakeholders. The next round, we’ll finish Odin. The following, Fafnir. The project is done.
Now there are some caveats to this approach. First, we still have work streams waiting on others. This is just unavoidable in such a situation, so we may have later work streams doing design or investigation work while the Static Configuration team works on Thor. Alternatively, we can slowly ramp people into this project as their work streams become unblocked. They could also participate in some of the other work streams to move things along faster. Flexibility is the name of the game with this approach. Everyone should be ready to do what’s needed at any given time.
So where does that leave you, our project lead? You will need to wear two hats. First, manage the graph traversal. Keep track of the progress being made on each item and what downstream impacts it may have. You may need to shuffle people around to keep things balanced. Second, work through the more complex issues where your technical guidance may be needed.
Monitor and adjust
This project system is a complex dance of timings and downstream impacts, and needs close monitoring and rapid adjustment. If any one work stream starts lagging behind, it could delay the entire project significantly.
You will need to move people around and find creative ways to work around dependencies. This is a highly dynamic process that can only be managed through good KPIs and an attentive project leader.
Conclusion
Leading large projects can be overwhelming and intimidating at first, but at its core, you just need to find the right system. Example One shows us a basic system where the work aligns to the software being built. Example Two demonstrates a more complex arrangement where you opt to align the work to the problem or solution spaces at hand.
In both cases, you’re ultimately aligning to some understandable sequence implicit in the work itself. Learning to identify how the work is structured naturally will enable you to apply the right approach for any given project.
Questionably Functional is a reader-supported publication, providing a single free article monthly with weekly paid articles. If you found this article helpful and would like more, please subscribe below.
Some employers may allow you to expense subscriptions to industry newsletters under their Education or Development budgets. Click here for more information.
If you have a question or topic that’s been on your mind, and you’d like my opinion on it, you can submit a question using the link in the navigation bar. Thank you!